最近学习卡尔曼滤波, 发现了一篇很好的博客. 也就是从这篇博客开始, 才逐渐开始理解卡尔曼滤波.
这篇博客没有像其他很多教程那样用一大堆公式让初学者望而却步. 但是看完之后, 你会发现你不仅理解了卡尔曼滤波的过程, 也对那些看着头痛欲裂的数学公式有所了解.
个人感觉这是一篇很棒的文章.
由于原文章是英文的, 这里将其翻译为中文.(由于水平有限, 翻译的质量本人也不敢恭维, 请见谅!)
如果英文水平还可以, 建议直接阅读原英文文章. 这里给出原文链接. How a Kalman filter works, in pictures
如有侵权, 请联系我删除 !(博客末尾有本人邮箱联系方式)
一千年以后-林俊杰
翻译如下:
注意: 如果文中数学公式加载错误, 请刷新后重试
卡尔曼滤波可以做什么
让我们看一个玩具的例子: 假设你有一个可以在树林中运动的小机器人, 这个机器人需要确切的位置用于导航。
这个机器人有一个状态$\vec {x_k}$, 它包含位置和速度信息。
$$
\vec{x_k} = (\vec{p}, \vec{v})
$$
注意状态仅仅是关于你的系统底层配置的一系列数字,它可以是任何数字.在我们的例子中它是位置和速度, 但它可以是有关水池中的液体量的数据, 可以是汽车引擎的温度, 可以是用户手指在触摸板上的位置, 或者是任何你需要跟踪的数据.
我们的机器人同时有一个精度是10米的GPS传感器, 这很好, 但是我们需要知道机器人的位置精度要高于10米. 在树林中有大量的水沟和悬崖, 如果机器人运动出错超过几英尺, 他可能会掉下悬崖. 所以它携带的GPS传感器不是足够的好.
我们可能也知道一些关于机器人运动的信息. 例如, 它知道发送给机器人动机的指令, 它知道如果它一直不受干扰的向着一个方向前进, 在下一个瞬间它可能会在相同的方向走的更远. 当然它不知道关于电机的所有信息: 它可能受到风的冲击, 轮子可能有一点打滑, 或者是滚过崎岖不平的地形; 所以车轮转动的数量可能并不完全代表机器人实际行驶的距离,这样的预测是不完美的.
GPS 传感器 告诉了我们一些关于机器人状态的信息, 但仅仅是间接的, 并且伴随着一些不确定性和不准确性. 我们的 预测 告诉我们一些机器人如何移动的信息,但只是间接的, 同样伴随着一些不确定性和不准确性.
但是如果我们使用所有可用信息, 我们是否能够得到一个比估计更好的答案? 当然答案是肯定的, 这就是卡尔曼滤波的作用.
卡尔曼滤波怎么看待你的问题
我们看一下我们尝试解决的问题的背景. 我们继续用一个只有位置和速度信息的状态进行讨论.
$$
\vec{x} = \begin{bmatrix}
p\\\\
v
\end{bmatrix}
$$
我们不知道实际的位置和速度是什么; 有大量位置和速度的组合可能是正确的.但是有一些组合会比其他组合更有可能.
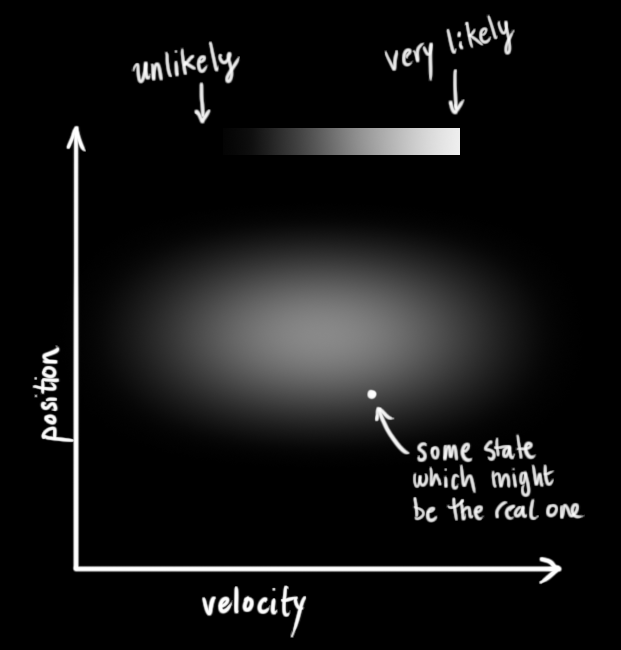
卡尔曼滤波假设所有变量(在我们的例子中是位置和速度)都是随机的并且符合高斯分布. 每一个变量都有一个均值$\mu$, 它是随机分布的平均值(它也是最可能的状态), 和一个方差$\sigma^2$, 它表示了不确定度.
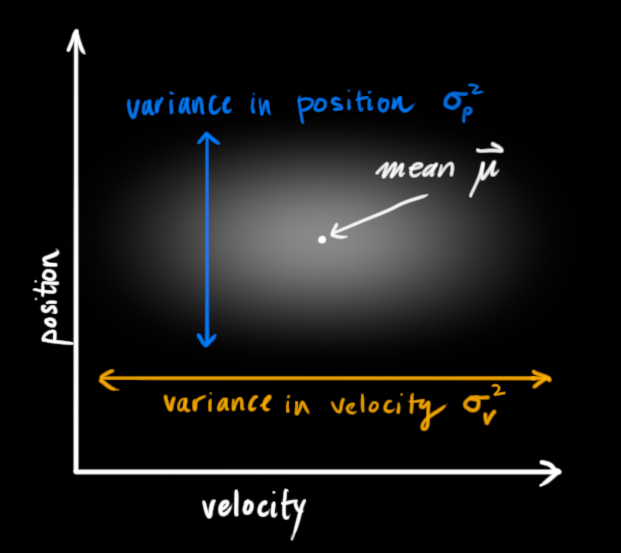
在上面的图片中, 位置和速度是不相关的, 意味着一个变量的状态不会告诉你其他变量可能的任何信息.
下面的例子展示了一些更有趣的事情: 位置和速度是相关的.观察到一个特定位置的可能性取决于你拥有的速度.
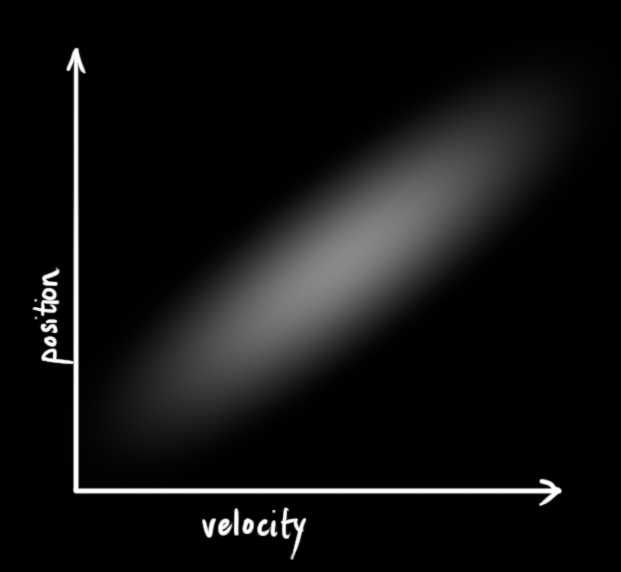
这种情况是可能出现的, 例如, 你正在基于一个旧的位置估计一个新的位置.如果我们的速度很高, 我们可能移动的更远, 因此我们的位置将会更远. 如果我们移动的比较慢, 我们就不能达到那么远.
这种关系对于跟踪数据非常重要,因为它为我们提供了更多信息: 一个测量数据告诉了我们一些关于其他数据可能的信息. 这就是卡尔曼滤波的目的, 我们希望尽可能地从我们不确定的测量中得到更多的信息.
这种相关性可以用协方差矩阵描述. 总之, 矩阵$\Sigma_{ij}$的每一个元素是第i个状态变量和第j个状态变量的相关度.(您可能会猜到协方差矩阵是对称的,这意味着如果交换i和j是无关紧要的). 协方差矩阵通常标记为“$\Sigma$”,因此我们将其元素称为“$\Sigma_{ij}$”。
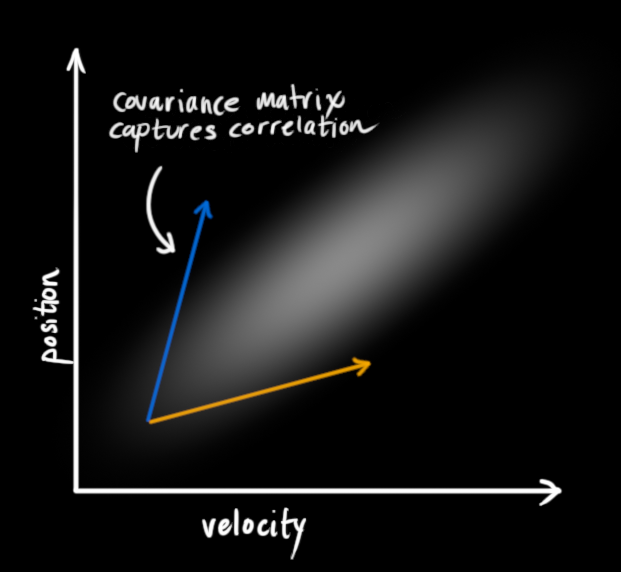
用矩阵描述问题
我们将关于机器人状态的信息建模为斑点, 因此我们需要时间k时的两条信息: 我们将把我们的最佳估计称为$\mathbf{\hat{x}_k}$ (均值, 也称为$\mu$), 和它的协方差矩阵$P_k$
$$
\mathbf
{ \hat{x}_k } =
\left[
\begin{matrix}
\text{position}\\\
\text{velocity}
\end{matrix}
\right]
\\\
P_k =
\left[
\begin{matrix}
\Sigma_{ pp } & \Sigma_{pv} \\\
\Sigma_{vp} & \Sigma_{vv}
\end{matrix}
\right]
$$
当然我们在这里只使用位置和速度,但是请记住, 状态可以包含任意数量的变量, 用来代表你想要的任何东西.
接下来,我们需要一些方法来查看当前状态(在时间k-1时)并预测在时间k时的下一个状态.
请记住,我们不知道哪个状态是“真正的”状态,但我们的预测功能并不关心这个。它适用于这些情况,并为我们提供一个新的分布.

我们可以使用矩阵 $F_k$重新表示这个预测步骤.
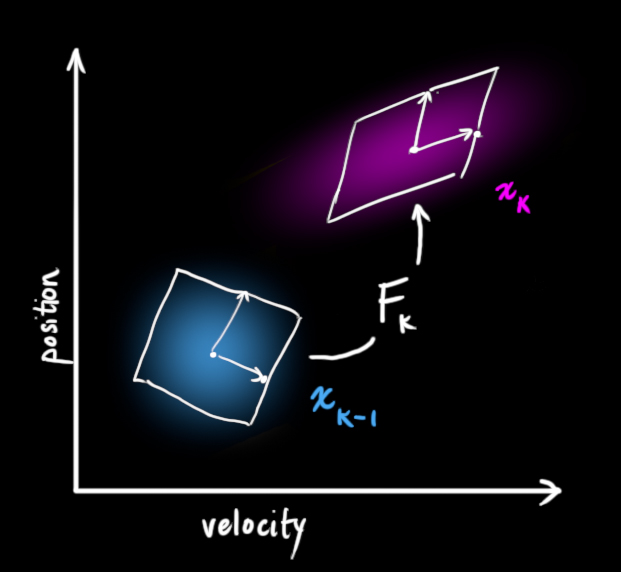
如果原估计是正确的, 它将原始估计的每一个点移动到一个新的预测位置.
让我们应用这个矩阵, 我们怎样使用这个矩阵预测接下来的一个瞬间的位置和速度呢?
我们将会使用一个非常基础的运动公式.
$$
{\color{deeppink}{p_k}} = {\color{royalblue}{p_{k-1}}} + \Delta t \color{royalblue}{v_{k-1}}
\\\
{\color{deeppink}{v_k}} = \color{royalblue}{v_{k-1}}
$$
换成矩阵的形式:
$$
{\color{deeppink} { \hat{x}}_k } =
\begin{bmatrix}
1 & \Delta t \\\\
0 & 1
\end{bmatrix} {\color{royalblue} { \hat{x}}_{k-1} }
= {F}_k {\color{royalblue} { \hat{x}}_{k-1} }
$$
现在我们有一个可以给出下一个状态的预测矩阵, 但是我们仍然不知道怎么更新它的协方差矩阵.
这里我们需要另外一个公式. 如果我们用一个矩阵A乘以一个分布的每一个点, 然后它的协方差矩阵将会怎么变化?
好, 它很简单. 这里给出定义:
$$
Cov(x) = \Sigma
\\\
Cov({\color{firebrick}{\mathbf{A}}}x) = {\color{firebrick}{\mathbf{A}}} \Sigma {\color{firebrick}{\mathbf{A}}^T}
$$
所以
$$
{\color{deeppink}{\mathbf{ \hat{x}}_k }} = \mathbf{F}_k {\color{royalblue}{\mathbf{ \hat{x}}_{k-1}} }
\\\
{\color{deeppink}{\mathbf{P}_k}} = \mathbf{F_k} {\color{royalblue}{ \mathbf{P}_{k-1}} } \mathbf{F}_k^T
$$
外部影响
但是, 我们还没有抓住一切影响状态的因素. 可能有一些变化和状态本身没有直接关系–外部世界可能会影响系统.
例如, 如果状态表示火车的运动, 火车司机可能会推动油门, 造成火车加速. 相似的, 在我们的机器人系统中, 导航软件可能会发出使轮子转动或者停止的命令. 如果我们知道这个关于外部世界将要如何变化的额外信息, 我们可以把它放进一个叫做$\color{darkorange}{\vec{\mathbf{u}_k}}$的向量, 用它做一些事情, 把它加入到我们的预测中作为矫正.
我们说由于我们知道了油门设置或者控制命令, 我们得到了期望的加速度$\color{darkorange}{a}$
由基础的运动学只是我们得到:
$$
{\color{deeppink}{p_k}} = {\color{royalblue}{p_{k-1}}} + {\Delta t} {\color{royalblue}{v_{k-1}}} + \frac{1}{2} {\color{darkorange}{a}} {\Delta t}^2
\\\
{\color{deeppink}{v_k}} = {\color{royalblue}{v_{k-1}}} + {\color{darkorange}{a}} {\Delta t}
$$
矩阵形式:
$$
{\color{deeppink}{\mathbf{\hat{x}}_k}} = \mathbf{F}_k {\color{royalblue}{\mathbf{\hat{x}}_{k-1}}} + \begin{bmatrix}
\frac{\Delta t^2}{2} \\\
\Delta t
\end{bmatrix}
\\\
{\color{darkorange}{a}}
= \mathbf{F}_k {\color{royalblue}{\mathbf{\hat{x}}_{k-1}}} + \mathbf{B}_k {\color{darkorange}{\vec{\mathbf{u}_k}}}
$$
$B_k$被称为控制矩阵, $\vec{u_k}$被称为控制向量.(对于没有外部影响的简单的系统, 你可以忽略它们).
让我们在多添加一个细节. 如果我们对于将要发生的预测不是一个100%精确的模型将会发生什么?
外部不确定性
如果事物的状态都基于自己的属性演变, 一切都很好. 同样, 如果其状态基于外部的影响变化, 一切仍然很好, 只要我们知道这些外部的影响都是什么.
但是对于我们不知道的影响怎么办? 例如, 我们正在跟踪一个四轴飞行器, 它可能会受到风的冲击. 如果我们正在跟踪一个轮式机器人, 它的轮胎可能会打滑, 可能会因为颠簸路面减速. 我们不可能考虑到一切外部影响, 如果这些外部影响中的任何一个发生了, 我们的预测就可能因为没有考虑到这些外部影响
而发生偏离.
我们可以通过在每一步预测之后添加一些新的不确定性来模拟与这个”世界”(即我们没有考虑的因素)相关的不确定性.
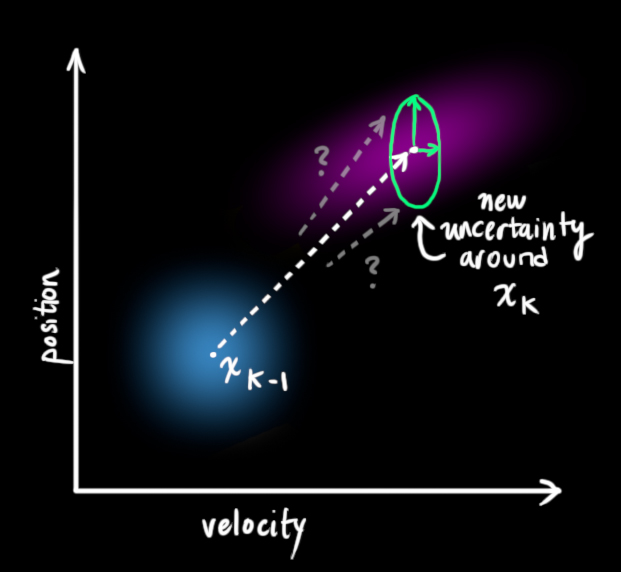
我们原始估计中的每一个状态都可以变为一系列的状态. 因为我们非常的喜欢高斯亮斑, 我们让$x_{k-1}$中的每一个点都移动到协方差为$Q_k$的高斯亮斑内部的某一个位置, 换句话说就是我们将没有考虑到的影响看做协方差为$Q_k$的噪声.
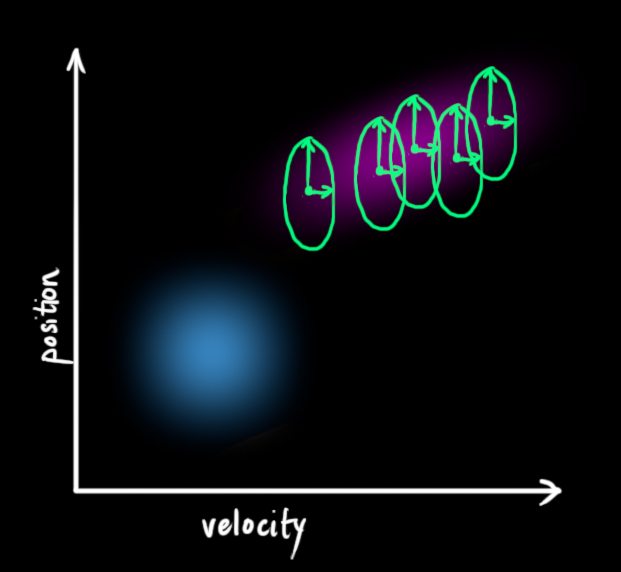
这样就产生了一个新的协方差不同的高斯亮斑(但是具有相同的均值).
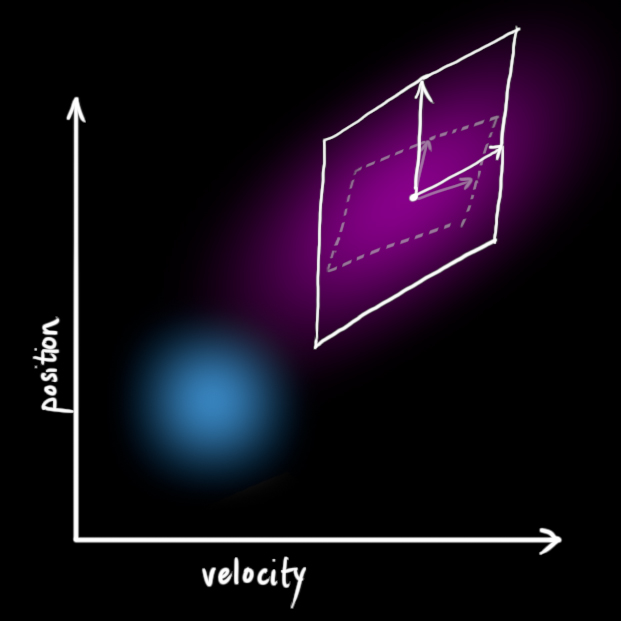
通过简单的增加一个$Q_k$, 我们得到了一个扩大的协方差, 这样就给出了预测部分完整的表达式.
$$
\begin{aligned}
\color{deeppink}{\mathbf{\hat{x}}_k} &= \mathbf{F}_k {\color{royalblue}{\mathbf{\hat{x}}_{k-1}}} + \mathbf{B}_k \color{darkorange}{\vec{\mathbf{u}_k}} \\\\
\color{deeppink}{\mathbf{P}_k} &= \mathbf{F_k} {\color{royalblue}{\mathbf{P}_{k-1}}} \mathbf{F}_k^T + \color{mediumaquamarine}{\mathbf{Q}_k}
\end{aligned}
$$
换句话说, 当前最优估计值是从上一次最优估计值得到的一个预测值, 同时加上一个对已知外影响的矫正.
同样, 当前不确定度是从上一次不确定度得到的一个预测值, 加上一些来自外部环境的不确定度.
好吧, 这很简单. 我们已经对我们系统的状态有了一个模糊的估计, 这个模糊估计由$\color{deeppink}{\mathbf{\hat{x}}_k}$和$\color{deeppink}P_k$ 给出.
通过测量细化估计
我们已经有了若干个可以给出系统状态信息的传感器。目前它们测量的数据并不重要;也许一个传感器读到的是位置,另一个得到的是速度。每一个传感器都可以告诉我们一些间接的状态信息–换句话说,传感器在某个状态下运行并且读取到一系列的信息。
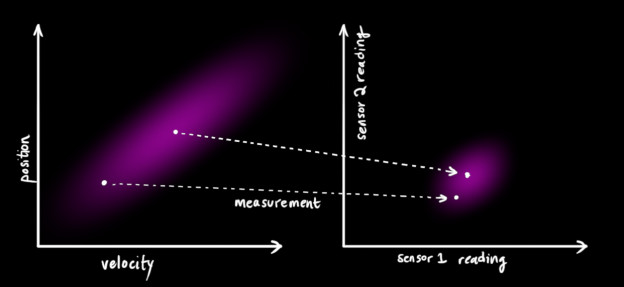
我们注意到读取信息的单位和范围可能与我们想要追踪的状态的单位和范围并不一致。你可能猜到了将要做什么了:我们将用一个矩阵$H_K$对传感器建模。
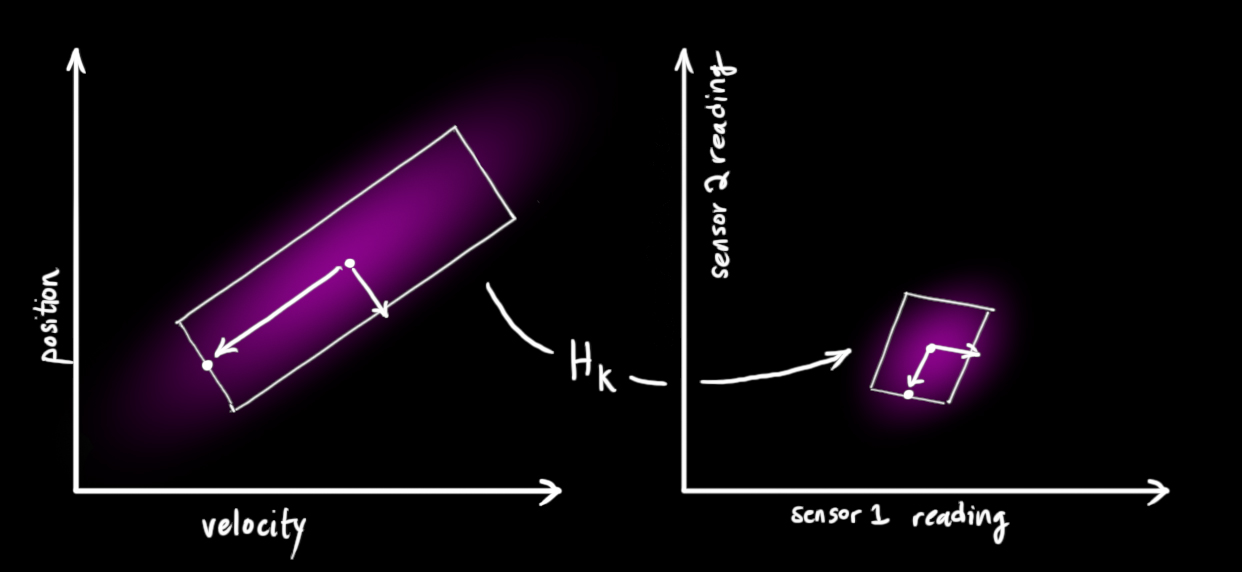
我们可以计算出传感器读取数据的分布像我们通常希望的那样。
$$
\begin{equation}
\begin{aligned}
\vec{\mu}_{\text{expected}} &= \mathbf{H}_k \color{deeppink}{\mathbf{\hat{x}}_k} \\\\
\mathbf{\Sigma}_{\text{expected}} &= \mathbf{H}_k \color{deeppink}{\mathbf{P}_k} \mathbf{H}_k^T
\end{aligned}
\end{equation}
$$
卡尔曼滤波擅长的一件事就是处理传感器噪声。换句话说,我们的传感器至少在一定程度上是不可信的,我们原始估计的每一个状态可能会产生一系列的传感器数据。
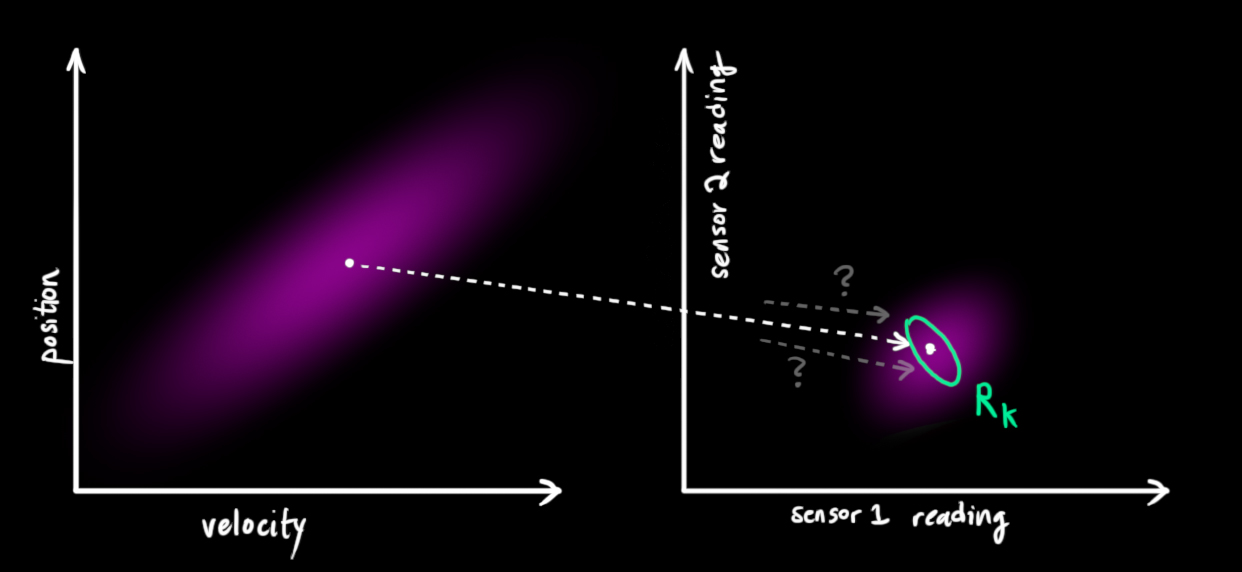
从观察到的每一个读取数据,我们可以猜测出出系统在一个特殊的状态。但是因为有不确定性存在,一些状态比其他状态更有可能产生我们所看到的数据:
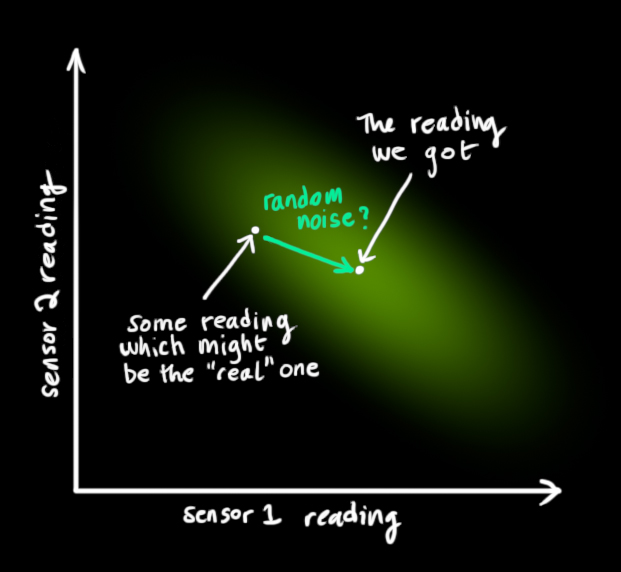
我们称不确定性(例如:传感器噪声)的协方差$\color{mediumaquamarine}{\mathbf{R}_k}$,分布的均值等于我们观察到的读取数据,我们称之为$\color{yellowgreen}{\vec{\mathbf{z}_k}}$.
现在我们有了两个高斯亮斑:一个在经过转化后的预测值周围,一个在我们得到的实际传感器数据周围。
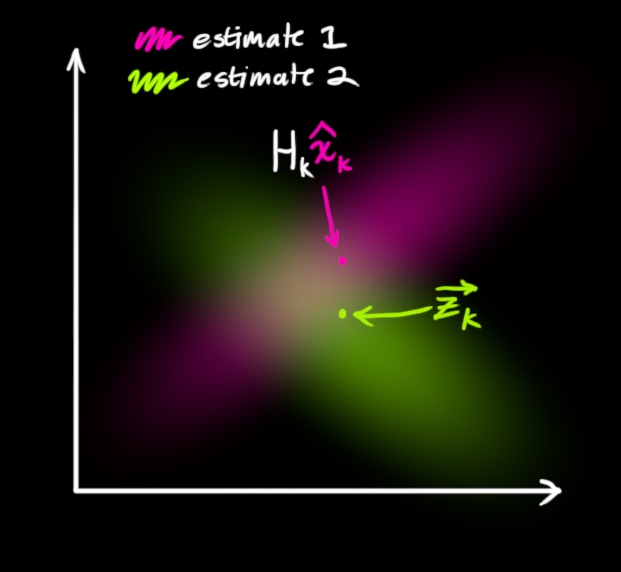
合并高斯分布
整合在一起
未完待续……

