上一篇博客提到了在图神经网络中应用比较广泛的GCN(Graph Convolutional Networks),这篇博客就来谈谈GAT(Graph Attention Networks)。
什么是GAT
什么是GAT呢?先看论文的名字”Graph Attention Networks“,图注意力网络,其实它的缩写应该是”GAN”,但是无奈这个名字已经被大名鼎鼎的”Generative Adversarial Network“捷足先登了,只能退而求其次称之为”GAT”了。
上面仅是个人猜想,如有雷同不甚荣幸,哈哈哈!下面言归正传。
GCN
对于GCN而言,要解决的问题是如何在非殴式数据(Non Euclidean Data)上进行卷积运算,为此大致分出两个派别,一派选择在Spatial domain上进行卷积运算,另一派则在Spectral domain上进行卷积运算。
- 对于Spatial approach,棘手的问题是如何处理graph data中每个顶点不同数量的邻居顶点和实现参数共享。
- 对于Spectral approach,该方法使用图上的傅里叶变换,将数据变换到频域进行处理之后再使用傅里叶逆变换回到时域,该方法很巧妙,但是受限于图的结构。该方法要求图的拉普拉斯矩阵是一个半正定的对称矩阵,因此Spectral domain的方法并不适合处理有向图和带权图等。
GAT
GAT则另辟蹊径,其引入注意力机制实现了图数据的特征表示(feature representation)。注意力机制可以处理变长的输入,同时通过注意力系数可以更多的关注输入中最相关的部分。
GAT有以下优点:
- GAT的操作是高效的
- 可以应用在有任意度的图节点上
- 可以应用到归纳学习(Inductive Learning)问题上
GAT 架构
Graph Attention Layer
GAT网络由多层的Graph Attention Layer组成。
对于每一层,输入是节点特征集合:
$$
h=\{\overrightarrow{h_{1}},\overrightarrow{h_{2}},…,\overrightarrow{h_{N}}\}, \overrightarrow{h_{i}} \in \mathbb{R}^{F}
$$
其中$N$ 是节点个数,$F$是节点特征的维度。
输出是新的特征集合:
$$
h^{\prime}=\{\overrightarrow{h_{1}^{\prime}},\overrightarrow{h_{2}^{\prime}},…,\overrightarrow{h_{N}^{\prime}}\}, \overrightarrow{h_{i}^{\prime}} \in \mathbb{R}^{F^{\prime}}
$$
其中$F^{\prime}$是新的节点特征的维度。
类似于CNN卷积层的输入是一个feature map,输出是一个新的feature map。
Attention Coefficient
对于输入的每一个节点特征$h_{i}$,首先使用一个可学习的权重矩阵$W$进行线性变换,$W \in \mathbb{R}^{F^{\prime}\times F}$ 。该参数对于所有节点是共享的,即每一层仅有一个$W$矩阵。
另外还需要学习一个注意力机制$a:\mathbb{R}^{F^{\prime}\times F} \to \mathbb{R}$,该机制负责计算各个节点对之间的注意力系数。
$$
e_{ij} = a(W\overrightarrow{h_{i}}, W\overrightarrow{h_{j}})
$$
上式计算了节点$j$对节点$i$的注意力系数,表示了节点$j$的特征对于节点$i$的重要性。上式表示计算任意节点对之间的注意力系数,是一种global attention机制。对于图结构数据,我们更关注该节点的邻接节点的特征,而不是所有节点。因此我们可以采用一种称为masked attention机制。
$$
e_{ij} = a(W\overrightarrow{h_{i}}, W\overrightarrow{h_{j}}), j \in \mathcal{N}_{i}
$$
其中$\mathcal{N}_{i}$表示节点$i$的邻居节点。
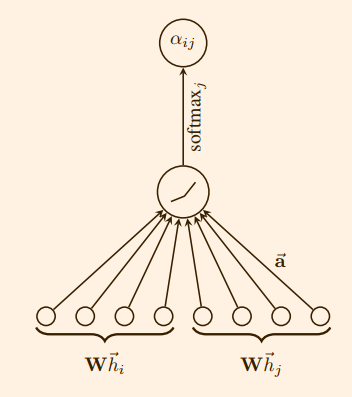
之后使用 softmax 对$e_{ij}$进行归一化处理。
$$
\alpha_{ij} = softmax_{j}(e_{ij}) = \frac{exp(e_{ij})}{\Sigma_{k\in \mathcal{N}_{i}} exp(e_{ik})}
$$
在GAT模型的实际处理中,$a$是一个向量,$\overrightarrow{a} \in \mathbb{R}^{2F^{\prime}}$,同时再为计算出的注意力系数添加一个激活函数,此处使用的是LeakyReLU函数。此时,注意力系数的公式可以表述为
$$
\alpha_{ij} = \frac{exp(LeakyReLU(\overrightarrow{a}^{T}[W\overrightarrow{h_{i}} || W\overrightarrow{h_{j}}]))}{\Sigma_{k\in \mathcal{N}_{i}} exp(LeakyReLU(\overrightarrow{a}^{T}[W\overrightarrow{h_{i}} || W\overrightarrow{h_{k}}]))}
$$
其中$||$是连接操作,因此连接后的 $[W\overrightarrow{h_{i}} || W\overrightarrow{h_{j}}]$ 的维度为 $2F^{\prime}\times 1$ ,而 $\overrightarrow{a} \in \mathbb{R}^{2F^{\prime}×1}$ ,则 $\overrightarrow{a}^{T}$ 的维度为 $1\times 2F^{\prime}$ ,所以最终得到的是一个实数,即注意力系数 $\alpha_{ij}$ 。
Linear Combination
计算得到的注意力系数$\alpha_{ij}$被作为节点$i$的邻居节点$j$对于节点$i$的重要性权重参与到计算节点$i$新的特征当中。节点$i$新的特征就等于其所有邻居节点$j$的特征的线性组合,线性组合的系数即为$\alpha_{ij}$。
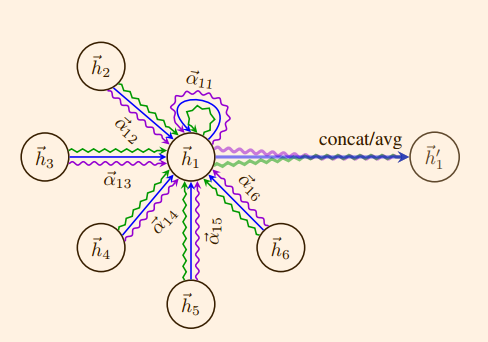
新特征的公式化表示为:
$$
\overrightarrow{h_{i}^{\prime}} = \sigma(\Sigma_{j\in\mathcal{N_{i}}} a_{ij}W\overrightarrow{h_{j}})
$$
这里添加了一个非线性激活函数$\sigma$。
Multi-head Attention
为了学习到更多的特征,可以使用multi-head attention策略,即在每一层学习$K$个权重矩阵$W$,每个权重矩阵都可以从$h_{i}$中提取到不同的特征。然后将学习到的$K$个特征连接(concatenation)在一起。multi-head attention类似于CNN网络中的多个卷积核。
$$
\overrightarrow{h_{i}^{\prime}} = ||_{k=1}^{K} \sigma(\Sigma_{j\in\mathcal{N_{i}}} a_{ij}^{k}W^{k}\overrightarrow{h_{j}})
$$
其中$||$表示连接操作,$a_{ij}^{k}$、$W^{k}$分别表示第$k$个 attention 的归一化注意力系数和权重矩阵。最终的输出$\overrightarrow{h_{i}^{\prime}}$是一个 $K\times F^{\prime}$ 维的向量。
特别的,如果Graph Attention Layer是最后一层,则不能使用 concatenation 操作,因为在最后一层我们希望得到的是一个实数(在分类问题中该实数可能表示的是属于某一类的概率,在回归问题中可能表示的是一个预测值),而非一个 $K\times F^{\prime}$ 维的向量。因此最后一层应该使用 average 操作,而不是 concatentation 。
$$
\overrightarrow{h_{i}^{\prime}} = \sigma(\frac{1}{K} \Sigma_{k=1}^{K}\Sigma_{j\in\mathcal{N_{i}}} a_{ij}^{k}W^{k}\overrightarrow{h_{j}})
$$
至此,GAT模型的结构介绍就完结啦。
GAT模型源码
Reference
- Graph Attention Networks,arxiv